AWS Data PipelineでDynamoDBのインポート/エクスポート
AWS Data Pipelineは、AWSのサービス間やオンプレ環境とのデータ転送を支援するサービスです。
複数のサービスを組み合わせることでETLツールのように使うこともできます。
今回はこれを使用してDynamoDBからデータのインポート/エクスポートを行ってみます。


公式マニュアルにあるサンプルテーブル「ProductCatalog」を作ってこれをエクスポートしてみます。
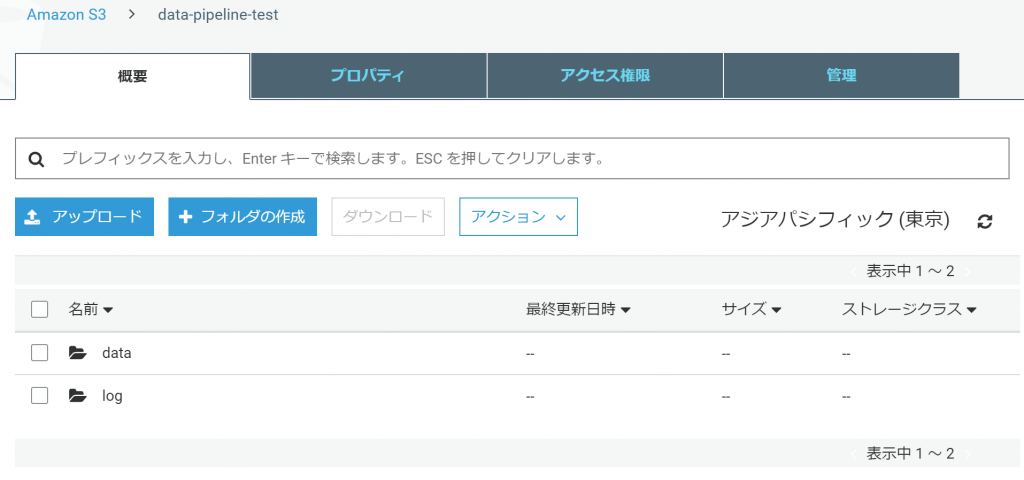
Data Pipelineのログもここに出力するので合わせて作っておきます。
バケット・フォルダには特段設定は必要ありません。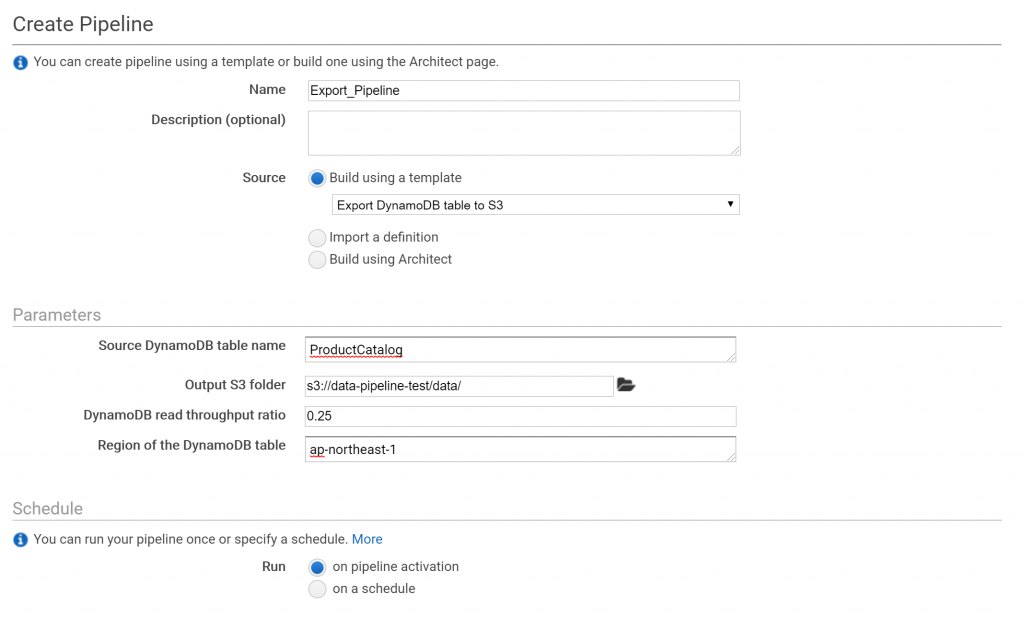
テーブルと出力先のS3フォルダを選びます。
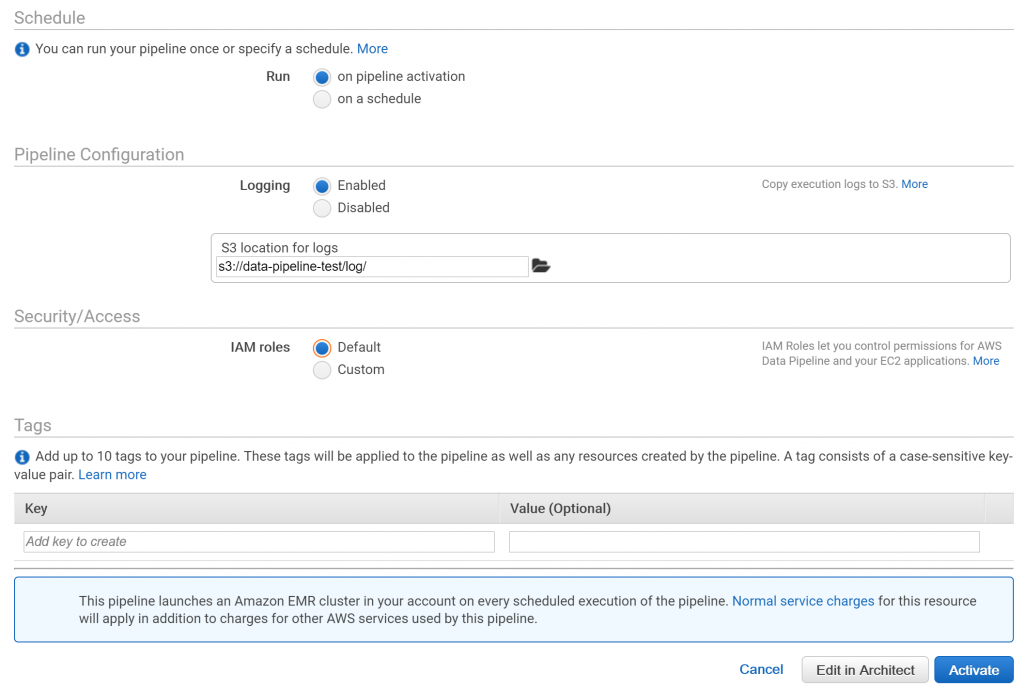
IAMロールはデフォルトを設定します。デフォルトのロールがなければ自動で作成されます。
「Edit in Architect」を押すとさらに細かい設定画面に移り、「Activate」を押すと、パイプラインがアクティブになります。
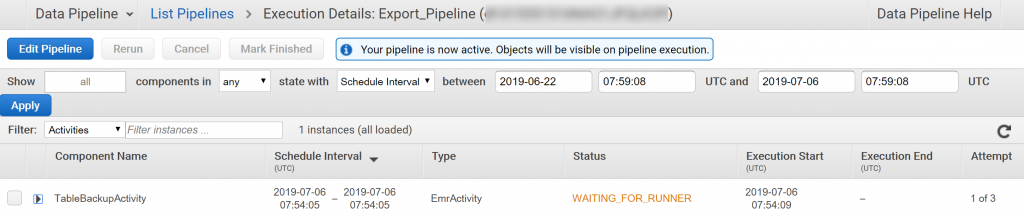
パイプラインを起動すると自動でAmazon EMRクラスタが作成され、EMRが使うためのEC2インスタンスも作成されます。
細かい進捗状態やエラーはEMRクラスタを見に行った方が分かりやすいです。
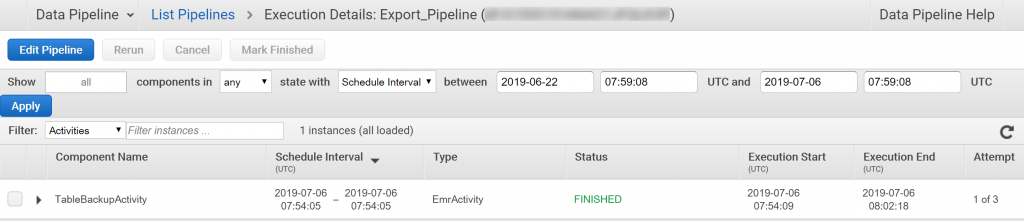
ステータスが「FINISHED」になれば完了です。
大体8分かかりました。
起動したEMRクラスタやEC2インスタンスは自動で破棄されます。
何らかの原因でパイプラインの処理が終わらない場合は、パイプラインを手動で止めないと動き続けてしまうため注意が必要です。
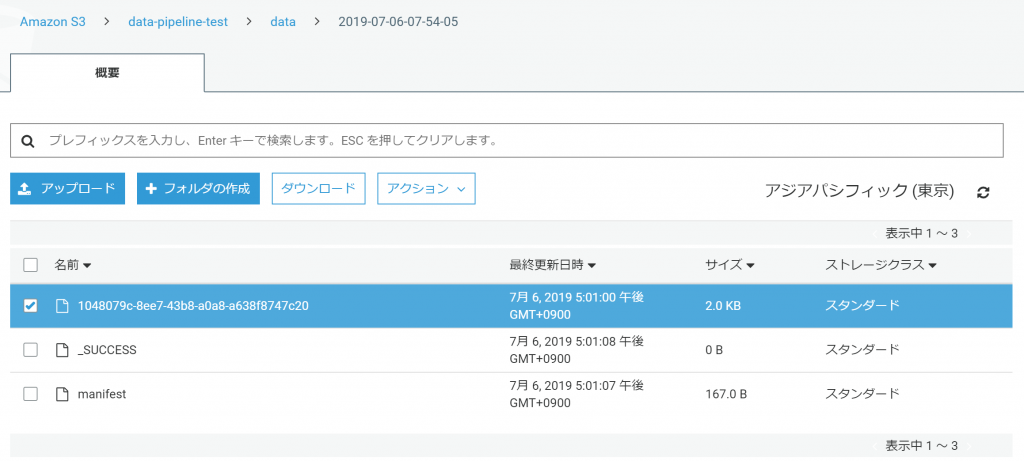
指定したS3フォルダにバックアップファイルができました。
中身はJSONです。
先ほどエクスポートしたファイルを「ProductCatalog」テーブルに戻してみます。
事前にテーブルの項目はすべて削除しておきます。
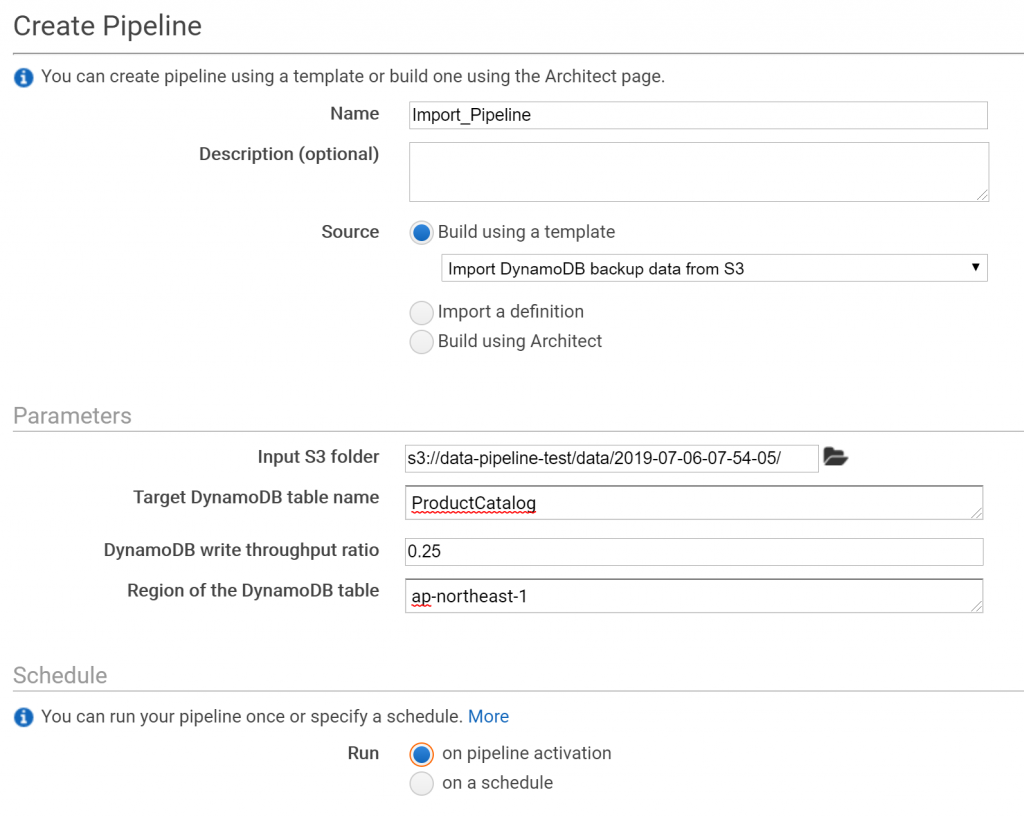
テンプレートは「Import DynamoDB backup data from S3」を選びます。
先ほどエクスポートしたフォルダを入力元に設定します。
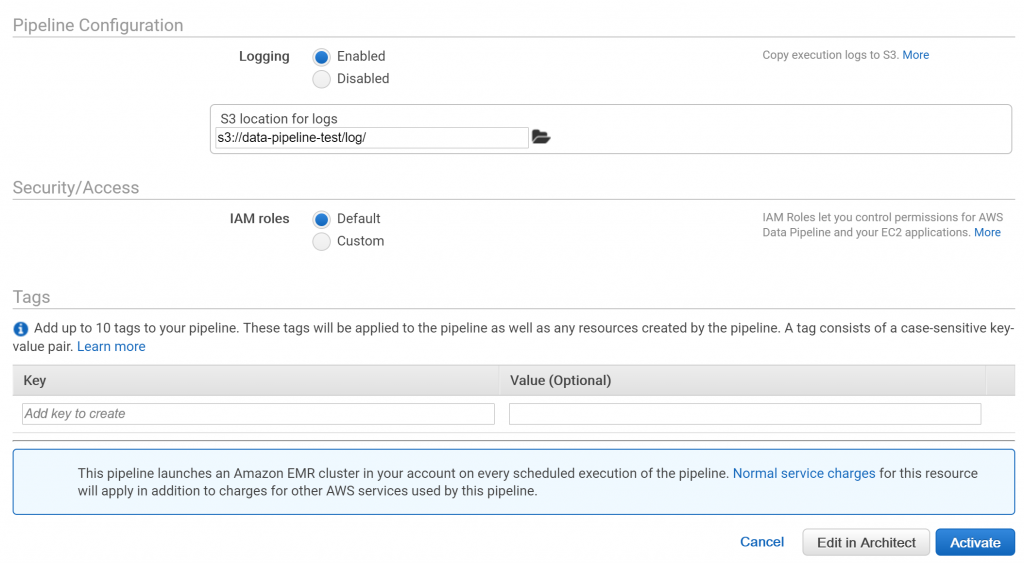
「Activate」を押して、パイプラインを実行します。
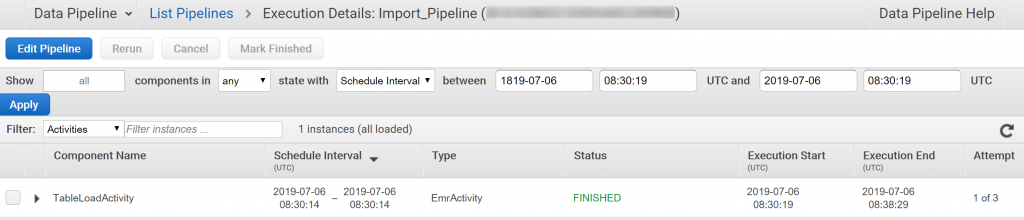
インポートも大体8分で終わりました。
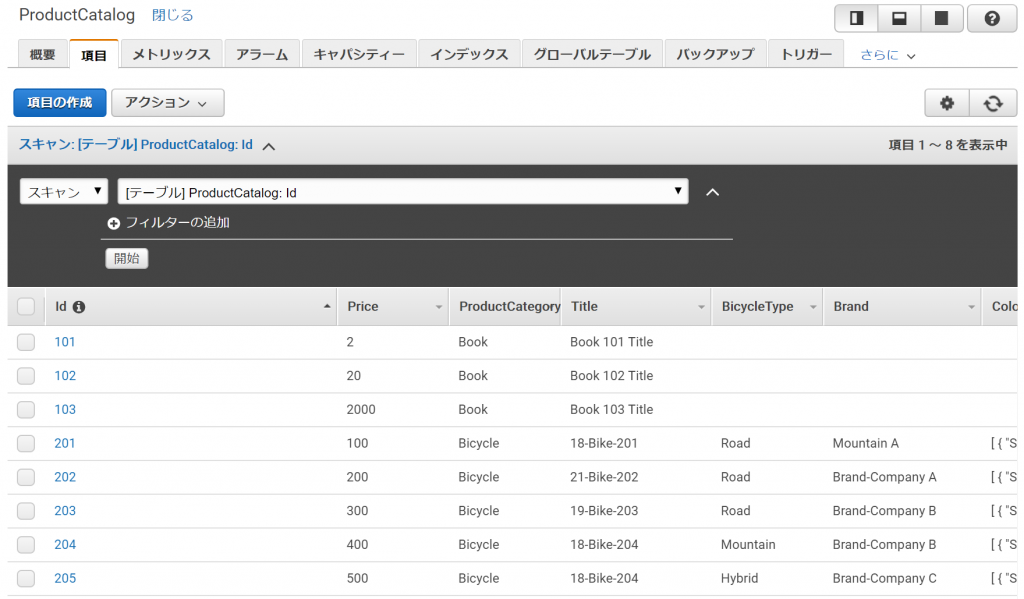
DynamoDBにデータが取り込まれています。
たかだか、インポート/エクスポートするだけですが、結構手間がかかります。
DynamoDBはGUIのデスクトップクライアントもないので、もうちょっと支援ツールが充実してくれると嬉しいのですが…。
ではまた。
複数のサービスを組み合わせることでETLツールのように使うこともできます。
今回はこれを使用してDynamoDBからデータのインポート/エクスポートを行ってみます。
目次
DynamoDBのエクスポート
まずは、DynamoDBのエクスポートから。
公式マニュアルにあるサンプルテーブル「ProductCatalog」を作ってこれをエクスポートしてみます。
エクスポート先のS3フォルダを作成
事前準備としてエクスポート先に指定するS3バケットとフォルダを作っておきます。Data Pipelineのログもここに出力するので合わせて作っておきます。
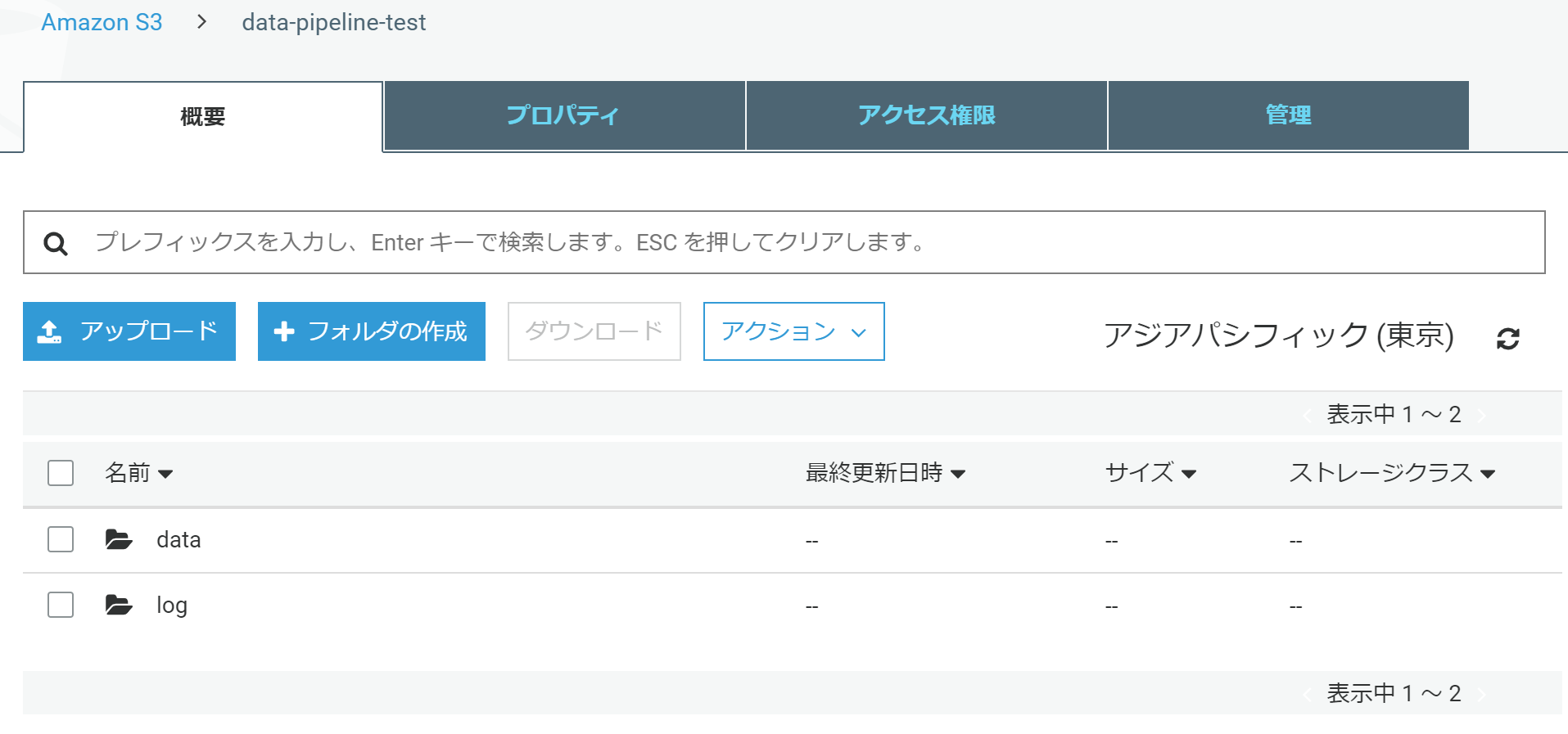
バケット・フォルダには特段設定は必要ありません。
エクスポート用パイプラインを定義する
それでは、エクスポート用のパイプラインを定義していきます。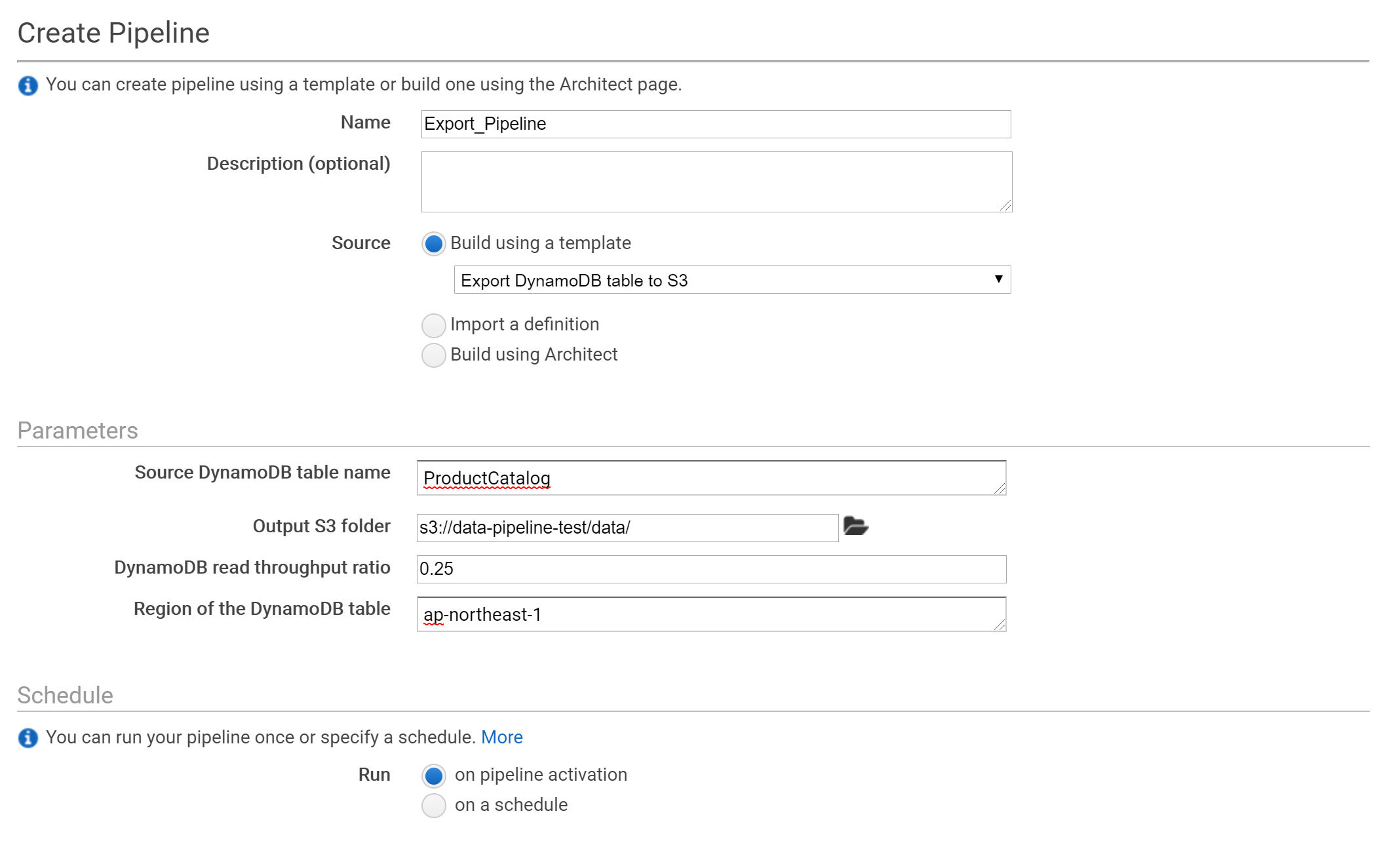
テーブルと出力先のS3フォルダを選びます。
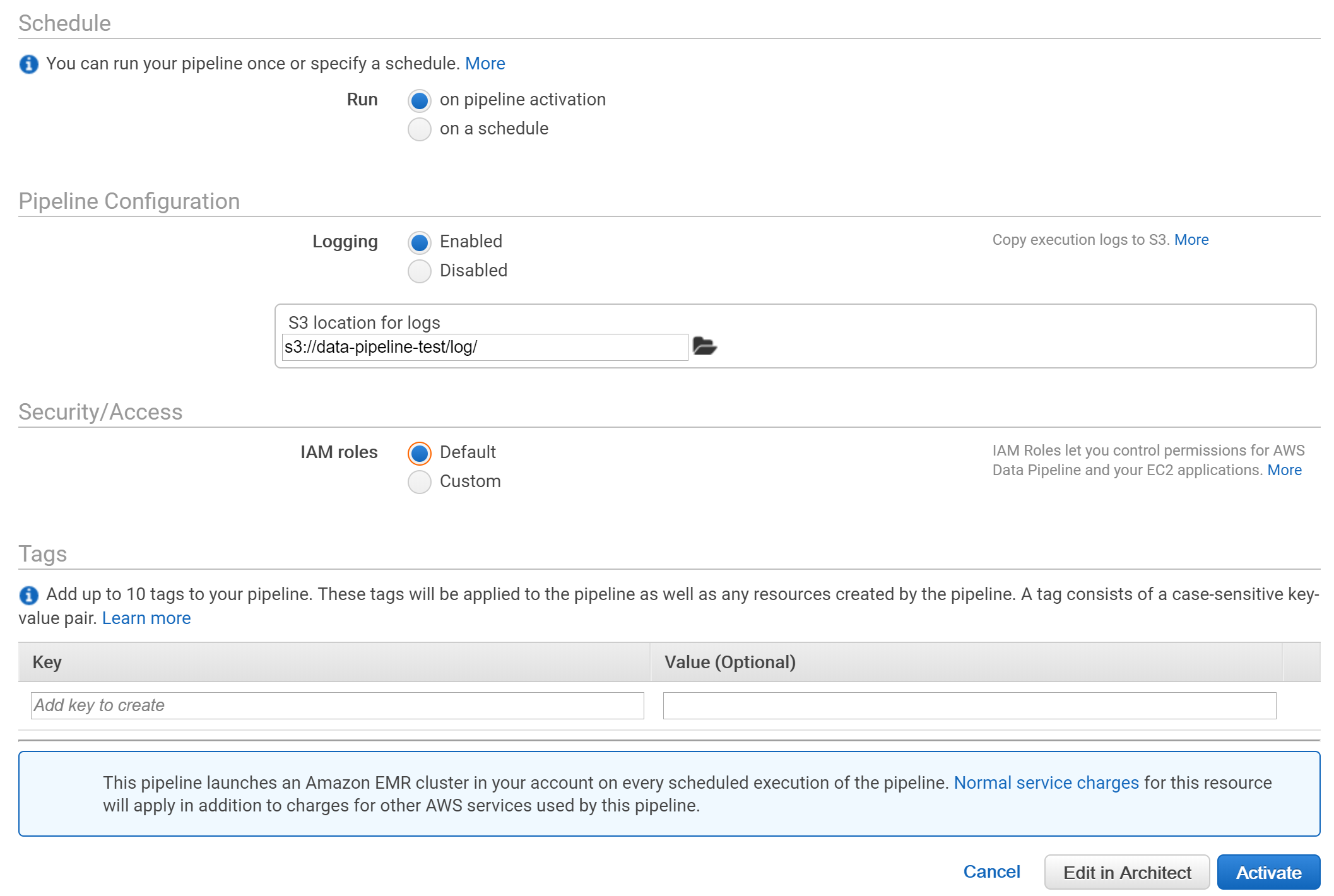
IAMロールはデフォルトを設定します。デフォルトのロールがなければ自動で作成されます。
「Edit in Architect」を押すとさらに細かい設定画面に移り、「Activate」を押すと、パイプラインがアクティブになります。
エクスポート用パイプラインを実行する
先の画面で「Activate」していれば、特にエラーがなければ実行されます。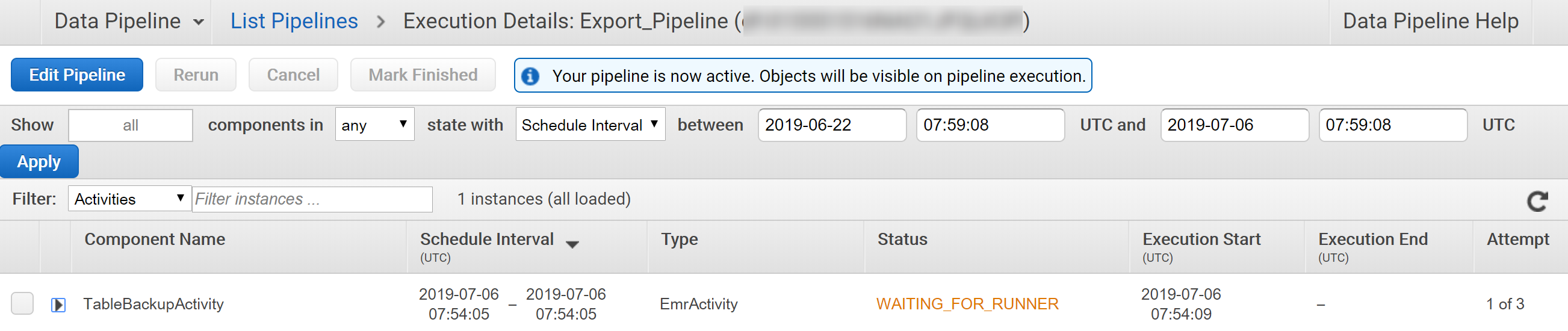
パイプラインを起動すると自動でAmazon EMRクラスタが作成され、EMRが使うためのEC2インスタンスも作成されます。
細かい進捗状態やエラーはEMRクラスタを見に行った方が分かりやすいです。
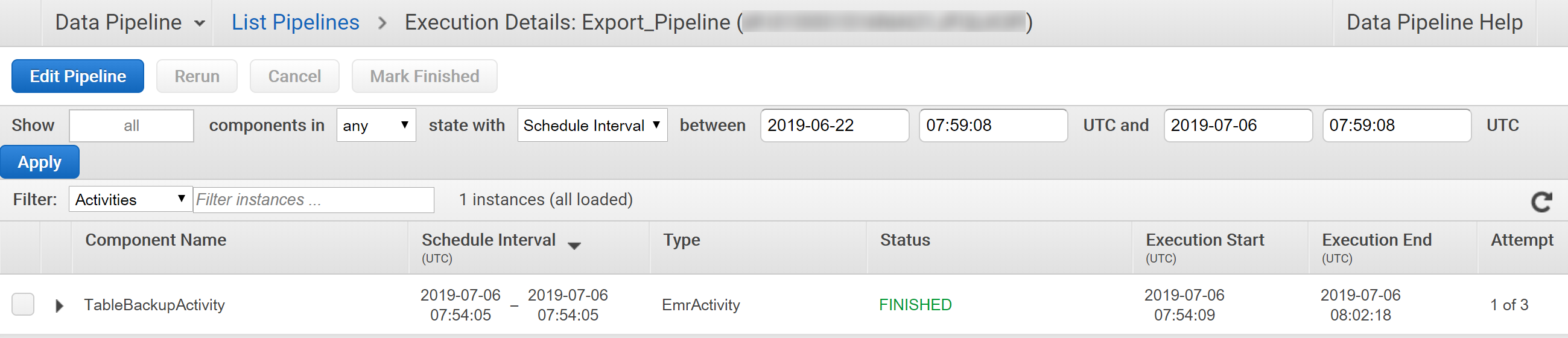
ステータスが「FINISHED」になれば完了です。

大体8分かかりました。
起動したEMRクラスタやEC2インスタンスは自動で破棄されます。
何らかの原因でパイプラインの処理が終わらない場合は、パイプラインを手動で止めないと動き続けてしまうため注意が必要です。
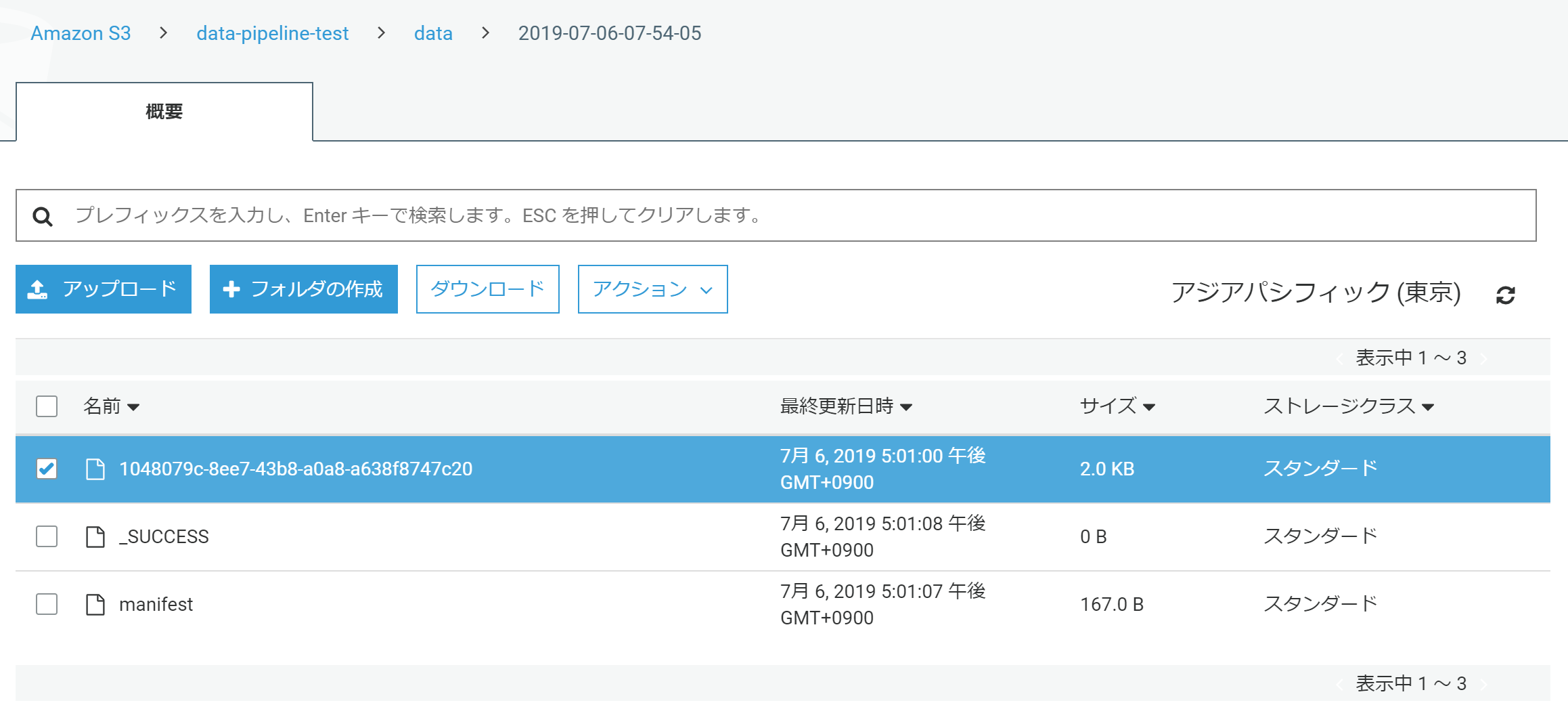
指定したS3フォルダにバックアップファイルができました。
中身はJSONです。
{"Brand":{"s":"Brand-Company C"},"Description":{"s":"205 Description"},"Price":{"n":"500"},"Color":{"l":[{"s":"Red"},{"s":"Black"}]},"ProductCategory":{"s":"Bicycle"},"Title":{"s":"18-Bike-204"},"Id":{"n":"205"},"BicycleType":{"s":"Hybrid"}}
{"Brand":{"s":"Brand-Company B"},"Description":{"s":"203 Description"},"Price":{"n":"300"},"Color":{"l":[{"s":"Red"},{"s":"Green"},{"s":"Black"}]},"ProductCategory":{"s":"Bicycle"},"Title":{"s":"19-Bike-203"},"Id":{"n":"203"},"BicycleType":{"s":"Road"}}
{"Brand":{"s":"Brand-Company A"},"Description":{"s":"202 Description"},"Price":{"n":"200"},"Color":{"l":[{"s":"Green"},{"s":"Black"}]},"ProductCategory":{"s":"Bicycle"},"Title":{"s":"21-Bike-202"},"Id":{"n":"202"},"BicycleType":{"s":"Road"}}
{"Brand":{"s":"Mountain A"},"Description":{"s":"201 Description"},"Price":{"n":"100"},"Color":{"l":[{"s":"Red"},{"s":"Black"}]},"ProductCategory":{"s":"Bicycle"},"Title":{"s":"18-Bike-201"},"Id":{"n":"201"},"BicycleType":{"s":"Road"}}
{"Brand":{"s":"Brand-Company B"},"Description":{"s":"204 Description"},"Price":{"n":"400"},"Color":{"l":[{"s":"Red"}]},"ProductCategory":{"s":"Bicycle"},"Title":{"s":"18-Bike-204"},"Id":{"n":"204"},"BicycleType":{"s":"Mountain"}}
{"InPublication":{"bOOL":true},"PageCount":{"n":"600"},"ISBN":{"s":"222-2222222222"},"Price":{"n":"20"},"Authors":{"l":[{"s":"Author1"},{"s":"Author2"}]},"ProductCategory":{"s":"Book"},"Title":{"s":"Book 102 Title"},"Dimensions":{"s":"8.5 x 11.0 x 0.8"},"Id":{"n":"102"}}
{"InPublication":{"bOOL":false},"PageCount":{"n":"600"},"ISBN":{"s":"333-3333333333"},"Price":{"n":"2000"},"Authors":{"l":[{"s":"Author1"},{"s":"Author2"}]},"ProductCategory":{"s":"Book"},"Title":{"s":"Book 103 Title"},"Dimensions":{"s":"8.5 x 11.0 x 1.5"},"Id":{"n":"103"}}
{"InPublication":{"bOOL":true},"PageCount":{"n":"500"},"ISBN":{"s":"111-1111111111"},"Price":{"n":"2"},"Authors":{"l":[{"s":"Author1"}]},"ProductCategory":{"s":"Book"},"Title":{"s":"Book 101 Title"},"Dimensions":{"s":"8.5 x 11.0 x 0.5"},"Id":{"n":"101"}}DynamoDBへインポート
今度は逆にDynamoDBへインポートを行ってみます。先ほどエクスポートしたファイルを「ProductCatalog」テーブルに戻してみます。
事前にテーブルの項目はすべて削除しておきます。
インポート用パイプラインを定義する
インポート用のパイプラインを定義します。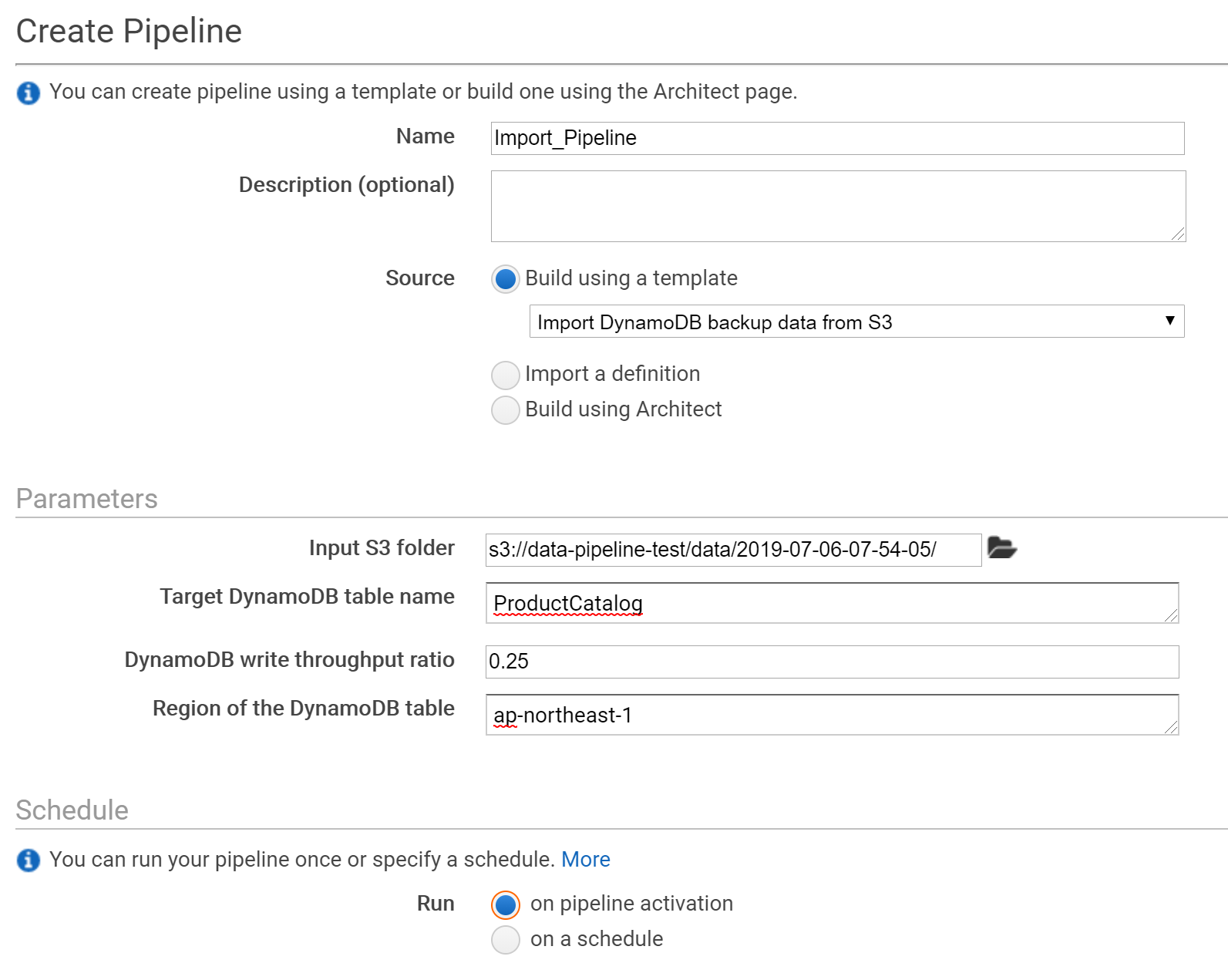
テンプレートは「Import DynamoDB backup data from S3」を選びます。
先ほどエクスポートしたフォルダを入力元に設定します。
「Activate」を押して、パイプラインを実行します。
インポート用パイプラインを実行する
エクスポート時と同じように、EMRクラスタが立ち上がり、処理が実行されます。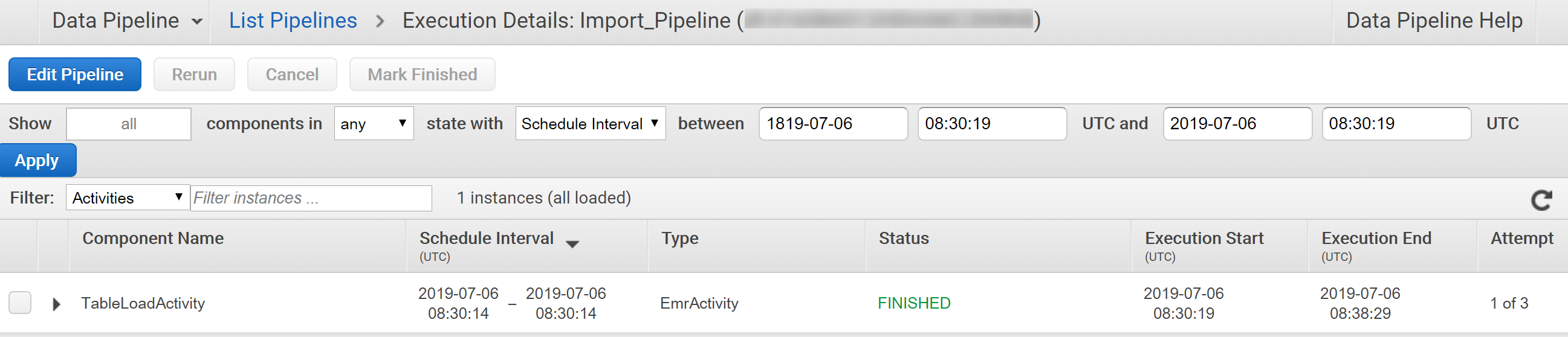
インポートも大体8分で終わりました。
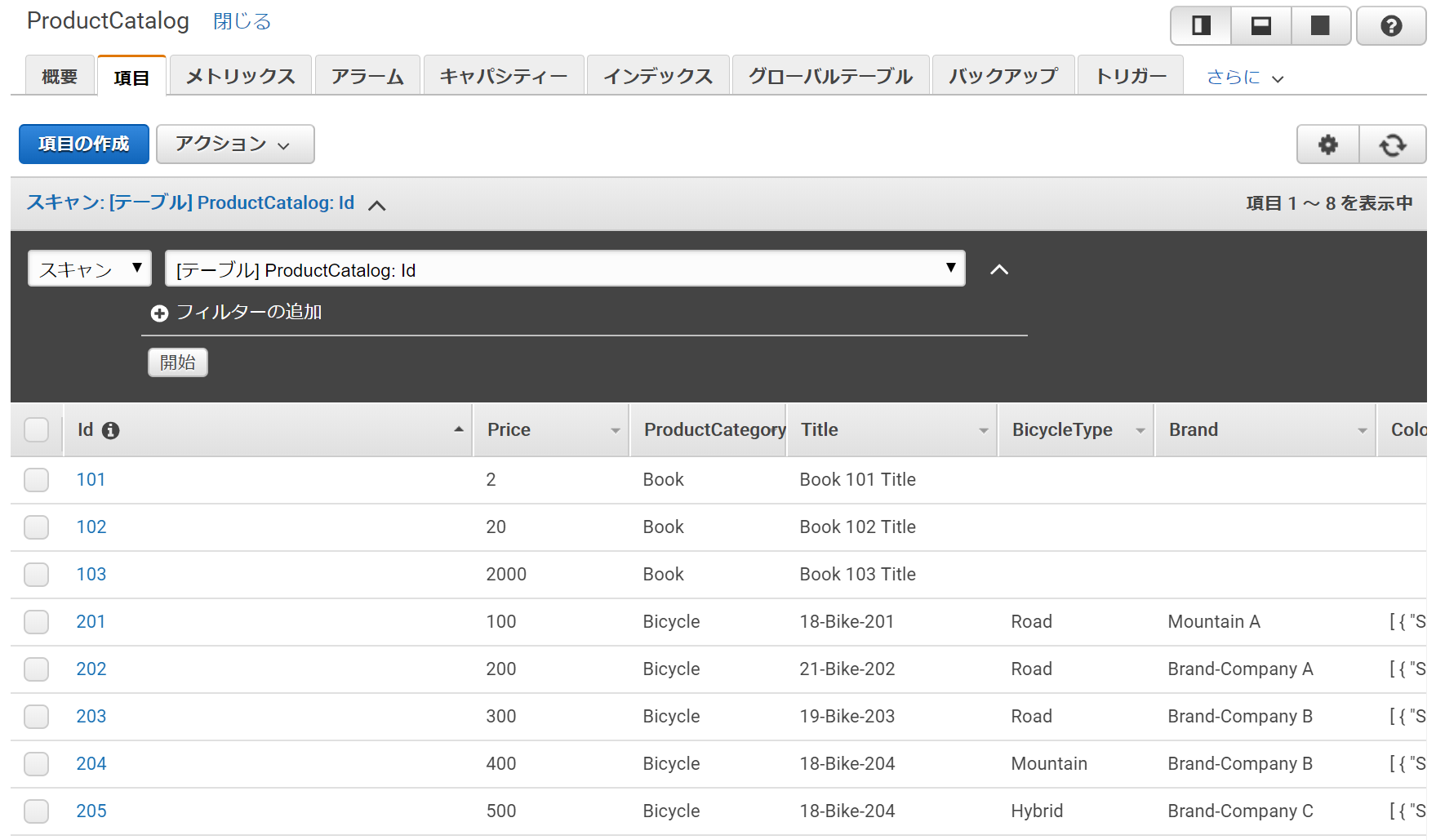
DynamoDBにデータが取り込まれています。
たかだか、インポート/エクスポートするだけですが、結構手間がかかります。
DynamoDBはGUIのデスクトップクライアントもないので、もうちょっと支援ツールが充実してくれると嬉しいのですが…。
ではまた。
