Amazon AthenaでS3上のデータをSQLで操作する
Oracle Databaseには外部表という機能があり、これはファイルシステムに置かれたCSVファイルをテーブルのようにSQLで検索できる機能です。
Amazon AthenaはS3バケットに置かれたデータをSQLでテーブルのように扱えるサービスです。
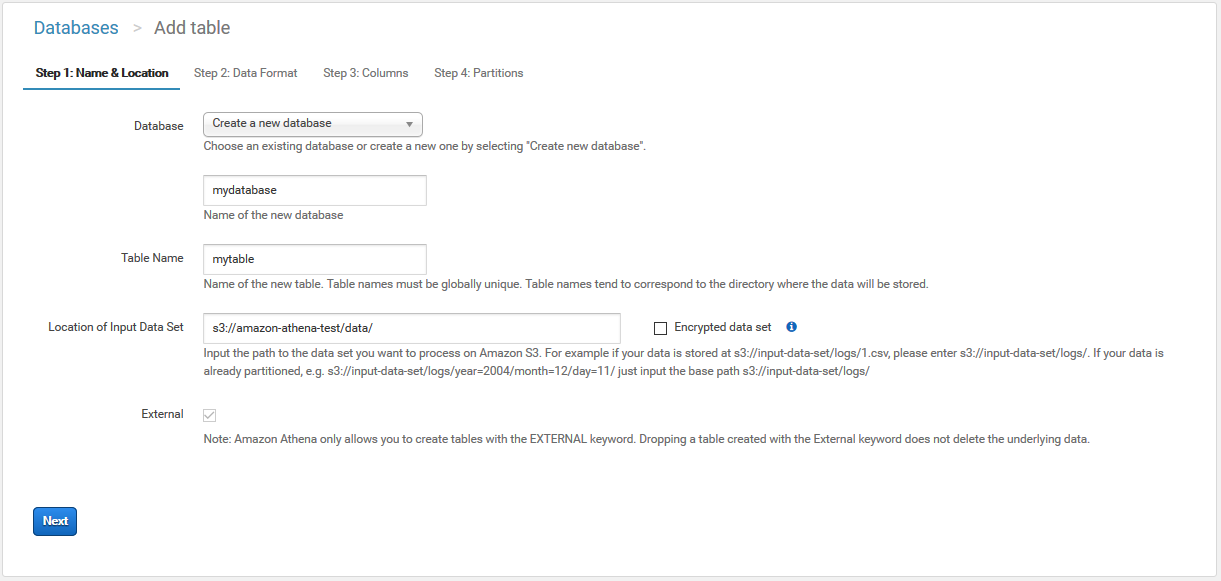
先ずはデータベースとテーブルを定義します。
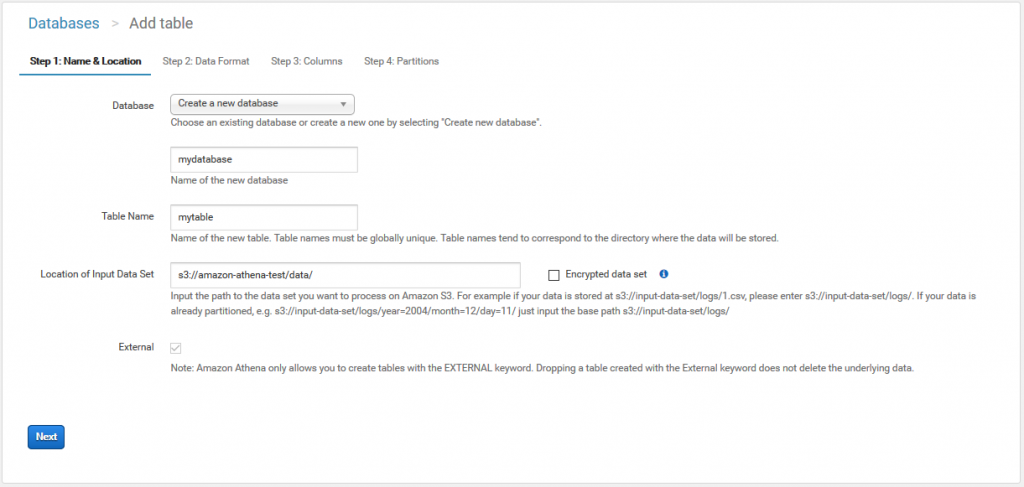
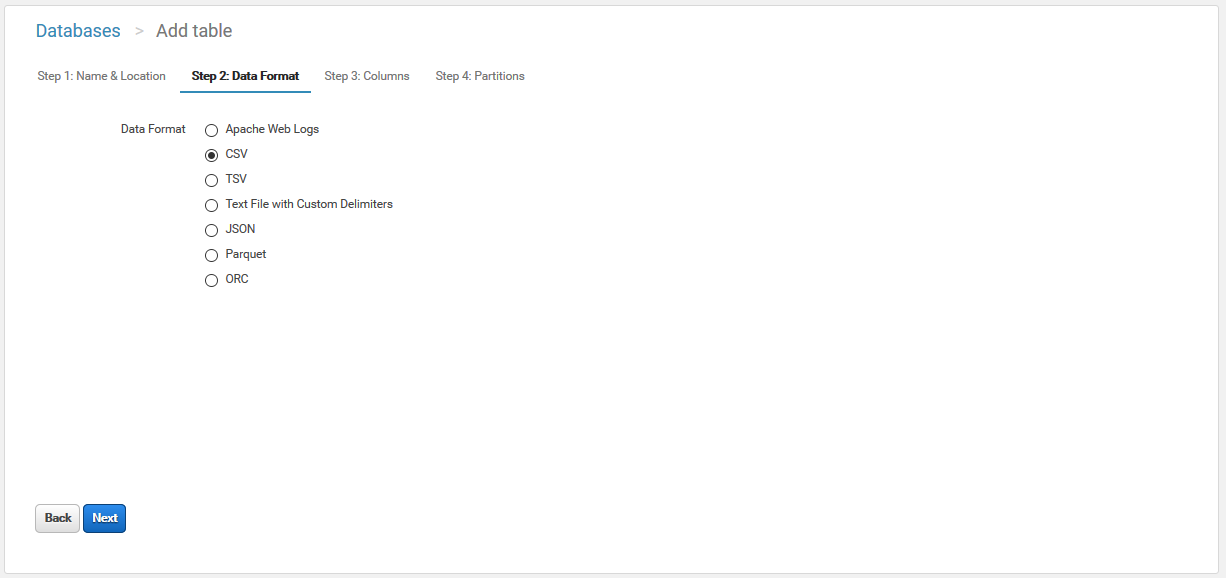
次にデータ形式を選択します。
今回はCSVで。
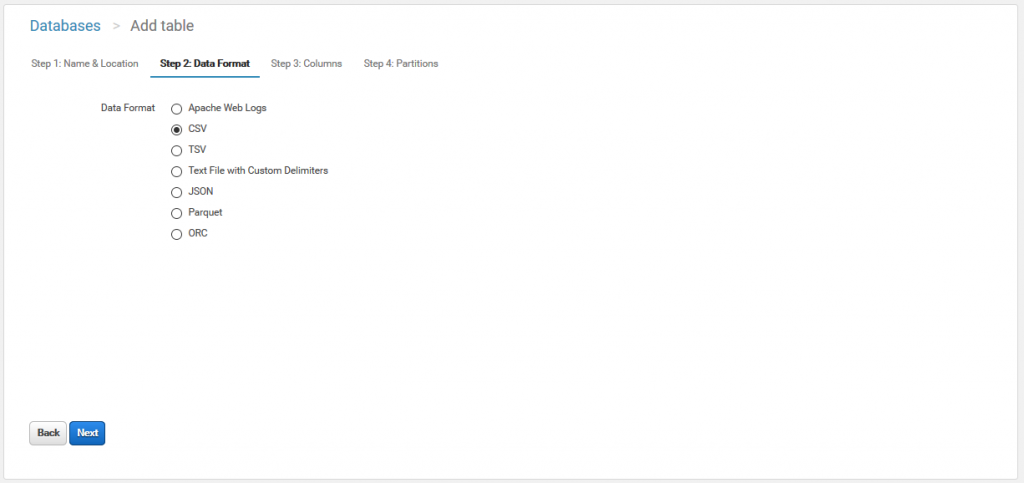
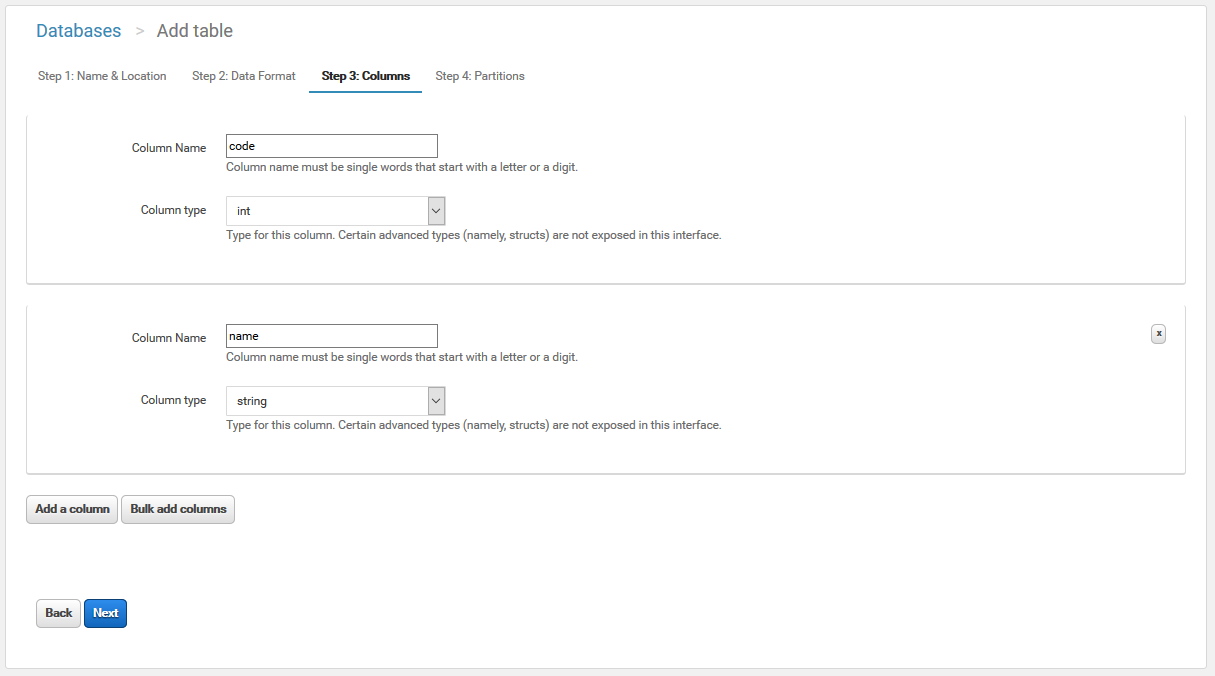
カラムを定義します。
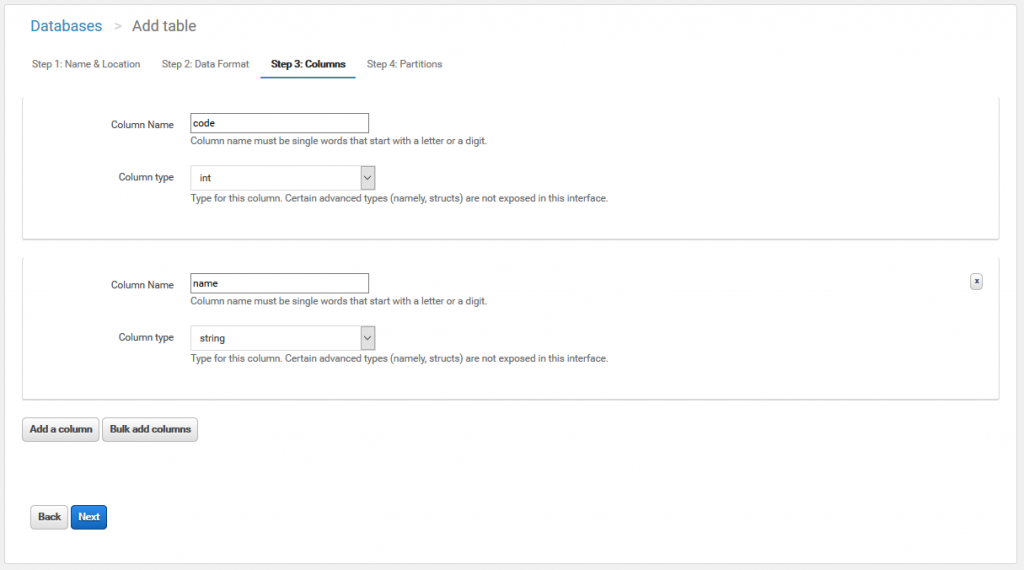
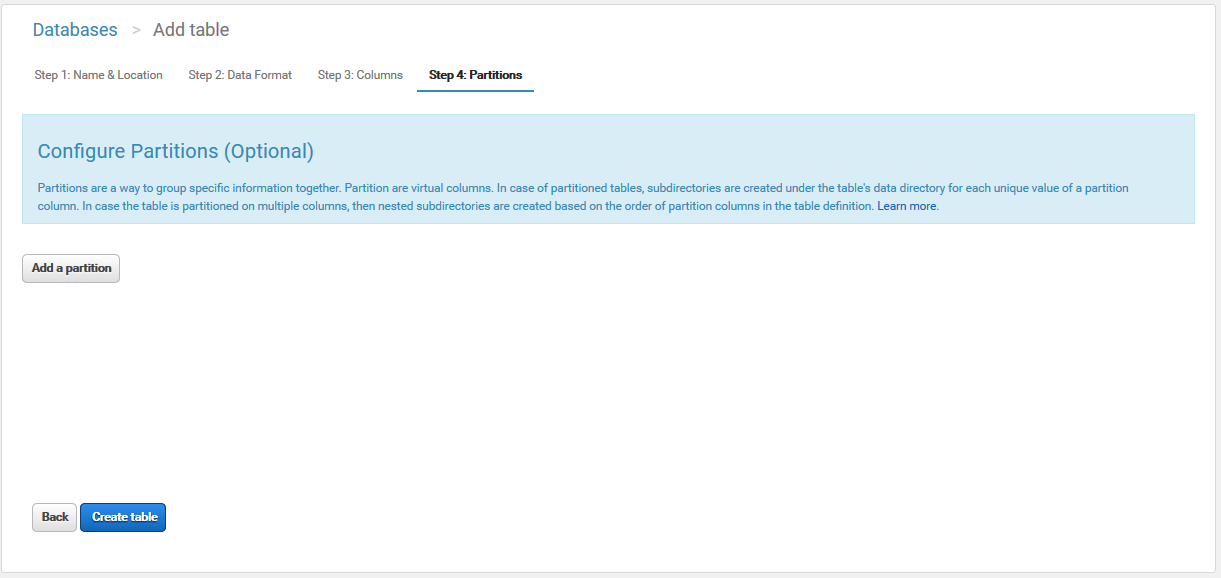
パーティショニングができるみたいですが、特に必要ないのでそのままテーブルを作成します。
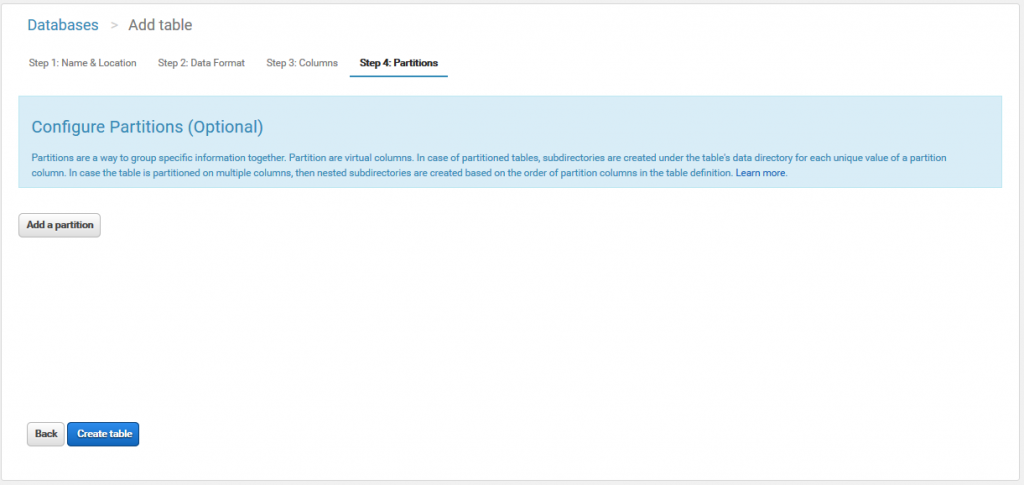
コンソールのSQLエディタに↓のSQLが表示・実行されます。
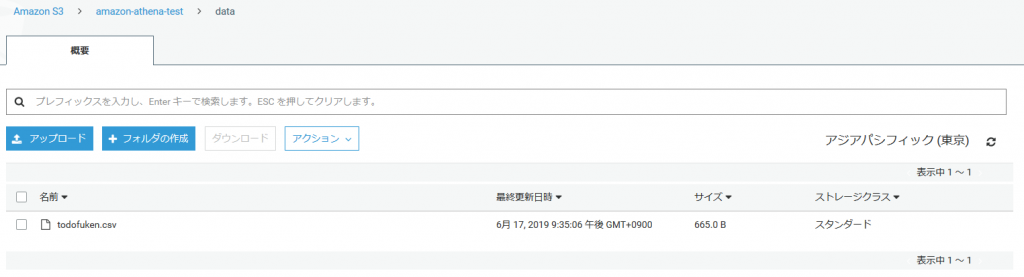
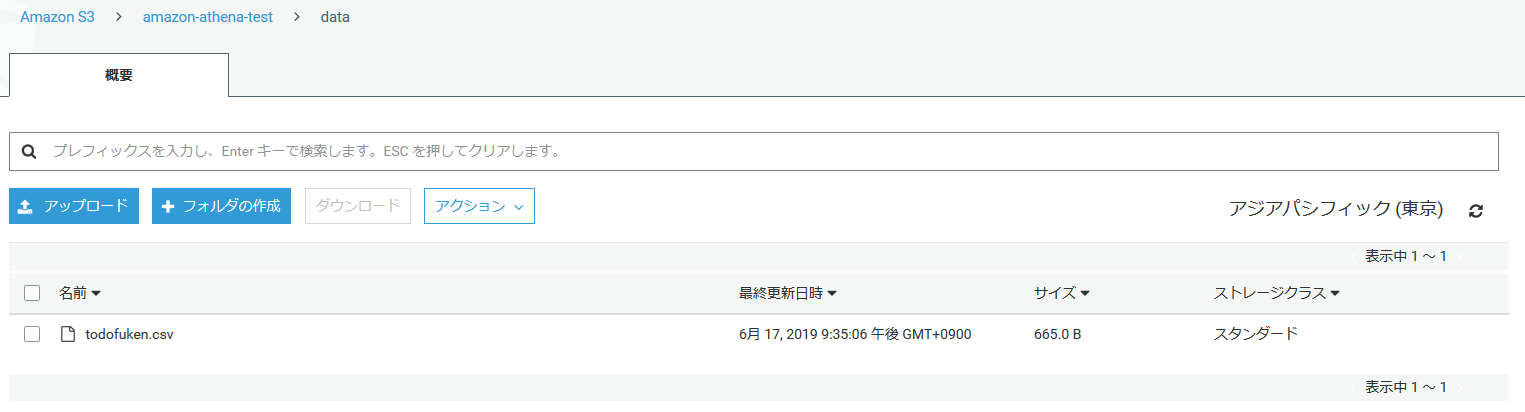
バケットに読み込み元のファイルを配置します。
中身は都道府県コードと都道府県名です。
フォルダ=テーブルとして認識するようです。
同一フォーマットのデータを同一フォルダに置けば、レコードが足されると。
ログファイルとかはその方が取り回しが楽そうですね。
これでDMLを発行する準備ができました。
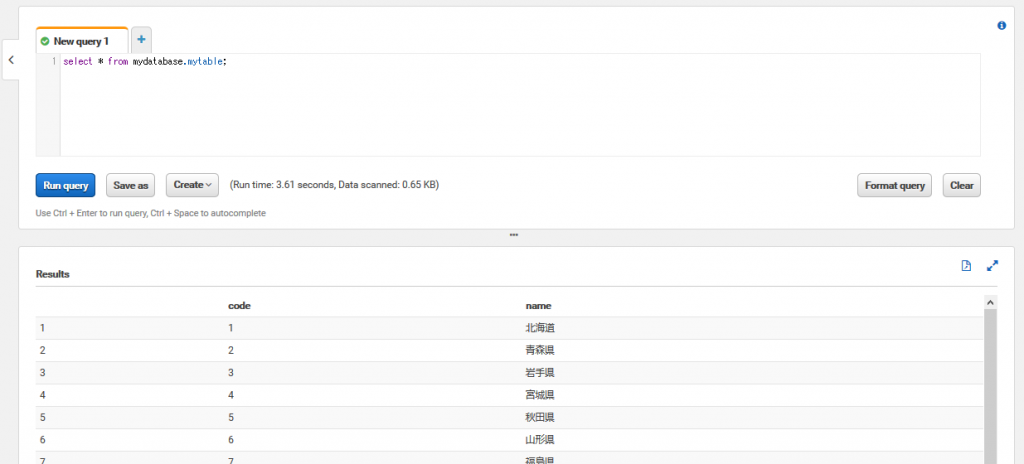
48件のレコード読み込みに3.61秒かかりました。
まあ、RDBではないので速さは期待できないですよね。
まあ、外部表だしそりゃそうか。
大量のログデータの参照や、システム同士のマスタ連携に使うのがベターですね。
今回はAWSのコンソールからクエリを発行しましたが、ODBCやJDBC経由での接続もできるようです。
↓のようにテーブル結合も使えるので、うまくログファイルを設計すれば、保守運用時のトラッキングが楽になりそうですね。
Amazon AthenaはS3バケットに置かれたデータをSQLでテーブルのように扱えるサービスです。
試してみる
先ずはデータベースとテーブルを定義します。
次にデータ形式を選択します。
今回はCSVで。
カラムを定義します。
パーティショニングができるみたいですが、特に必要ないのでそのままテーブルを作成します。
コンソールのSQLエディタに↓のSQLが表示・実行されます。
CREATE EXTERNAL TABLE IF NOT EXISTS mydatabase.mytable (
`code` int,
`name` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://amazon-athena-test/data/'
TBLPROPERTIES ('has_encrypted_data'='false');バケットに読み込み元のファイルを配置します。
中身は都道府県コードと都道府県名です。
01,北海道
02,青森県
03,岩手県
04,宮城県
05,秋田県
06,山形県
07,福島県
08,茨城県
09,栃木県
…フォルダ=テーブルとして認識するようです。
同一フォーマットのデータを同一フォルダに置けば、レコードが足されると。
ログファイルとかはその方が取り回しが楽そうですね。
これでDMLを発行する準備ができました。
SELECT
まずは普通にSELECTしてみます。select * from mydatabase.mytable;48件のレコード読み込みに3.61秒かかりました。
まあ、RDBではないので速さは期待できないですよね。
INSERT/UPDATE/DELETE
更新系のDMLは使用できません。まあ、外部表だしそりゃそうか。
大量のログデータの参照や、システム同士のマスタ連携に使うのがベターですね。
今回はAWSのコンソールからクエリを発行しましたが、ODBCやJDBC経由での接続もできるようです。
↓のようにテーブル結合も使えるので、うまくログファイルを設計すれば、保守運用時のトラッキングが楽になりそうですね。
select a.code,
b.name
from mydatabase.mytable a
left outer join mydatabase.mytable b
on a.code = b.code
order by 1
;